Random Lisp thoughts
I have covered about 4 chapters from the book Practical Common Lisp and what I have learnt so far is quite fascinating to say the least. Here're some random observations that I happened to make about Commmon Lisp. Please note that whenever I use the term Lisp below I refer to the Common Lisp dialect of the language.
Contrary to what one might conclude upon encountering a typical Lisp program, the basic Lisp syntax is actually quite minimalistic. It is so minimalistic in fact that I can probably explain all of Lisp syntax in about one line (OK, not all of it, but maybe a significant chunk of it - the point is, the basic structure of Lisp code is fairly straightforward)! Here goes:
Any Lisp code is a line of space delimited list of "things" and nested lists enclosed in parentheses.
By "things", I mean pretty much everything that can go into Lisp code. Here's some lisp code:
(believe it or not but this is some lisp code!)And here's another example with nested lists:
(lisp code (with nested lists))If you tried entering this stuff at an interactive Lisp shell prompt however, you are bound to have been slapped with some errors and that's because even though this conforms to Lisp code structure it really doesn't mean anything. Its like trying to feed some random bit of XML to an XSL parser, or trying to pass an XSL file to the ANT program. In each of these cases, though we are passing well-formed XML they don't exactly have the tags that the respective programs are looking for.
What we have accomplished with our definition above therefore is to specify what Lisp expressions are to look like. Imagine specifying the entire XML specification in one line (which of course is quite impossible because the actual spec runs to about 50 pages)! For a fully featured multi-paradigm programming language I think this is quite an incredible feat!
The technical Lisp term for what we have defined above is an s-expression. Any piece of valid Lisp code is always a valid s-expression but as you might have discovered if you tried getting a Lisp interpreter to parse the examples given above, not all valid s-expressions are valid Lisp code. And that is where the typical Lisp noob (such as yours truly) spends time learning the language. But as is perhaps self evident, the terseness of the basic syntax for Lisp code goes a long way in accelerating the learning process and all the apparently confounding parentheses actually end up being a rather natural way of doing things.
The basic Lisp form is so simple that I was able to whip up a little Lisp parser in JavaScript in about half an hour! Here's the complete parser:
// // Each node in the parse tree can be a list or a symbol. // var NodeType = { List: 0, Symbol: 1 }; // // Each node is defined by its type and content which in // turn can be another node (list) or a symbol name. // function Node(type, content) { this.type = type; this.content = content; } // // Helper function that generates a "Node" object given // a symbol name. // function symbol(sym) { return new Node(NodeType.Symbol, sym); } // // Helper function that generates a "Node" object given // a list object. // function list(lst) { return new Node(NodeType.List, lst); } // // Helper function that trims a string for leading/trailing white space. // String.prototype.trim = function() { return this.replace(/^\s+|\s+$/g, ""); } // // The Lisp lexer that can tokenize a string of Lisp code. // function Lexer(code) { this.code = code; var current = 0; var delims = "( )"; this.nextToken = function() { var token = null; // // skip all white-space only tokens // while (((token = internalNextToken.apply(this)) != null) && (token.trim().length == 0)); return token; } function internalNextToken() { // // if we have reached end of code then return null // if (current >= this.code.length) return null; // // accumulate characters into token till one of // the delimiters are encountered // var token = ""; for (; current < this.code.length; ++(current)) { var ch = this.code.charAt(current); if (isDelim(ch)) { if (token.length == 0) { token += ch; ++current; } break; } token += ch; } return token; } function isDelim(ch) { return (delims.indexOf(ch) != -1); } } // // The Lisp parser class that generates a parse tree composed of // "Node" object given a lexer object. // function Parser(lexer) { this.lexer = lexer; this.parseList = function() { var token; var lst = []; while (((token = this.lexer.nextToken()) != null) && (token != ")")) { switch (token) { case "(": lst.push(this.parseList()); break; default: lst.push(symbol(token)); break; } } return list(lst); }; this.parse = function() { // // the first token MUST be a "(" // if (this.lexer.nextToken() != "(") return null; return this.parseList(); }; } // // Parse some lisp code. // var code = "(sum (gen-multiples (gen-series 1000) 3 5))"; var parser = new Parser(new Lexer(code)); var root = parser.parse();This code simply generates an in-memory tree representation of the Lisp expression without performing any validation to check for correctness. This is akin to writing a non-validating DOM parser for XML - it simply hands you an object graph that you can programmatically traverse and do stuff with. I wrote a little HTML page to generate parse-tree visualizations given Lisp expressions of arbitrary complexity using the Google Visualization API and the Organizational Chart visualization in particular. Given the following Lisp expression for instance:
(sum (gen-multiples (gen-series 1000) 3 5))Here's the tree representation:
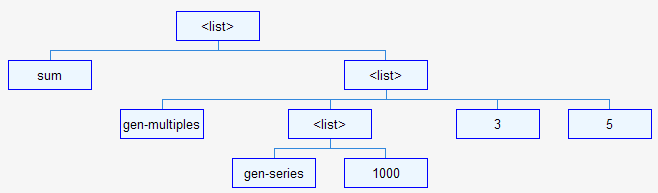
And for the following slightly more complex Lisp expression:
(sqrt (1+ (* (- (/ 28 2) 10) 2)))Here's the tree representation:
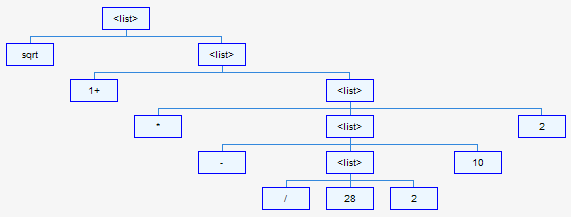
You can try building Lisp expression trees of your own at the following location:
Lisp s-expressions (i.e. valid Lisp form s-expressions) are of 3 types:
- Function calls
- Macro invocations
- Special forms
Function calls, are, well, function calls! In keeping with the minimalistic syntax philosophy, almost everything in Lisp is a function call (except of course, macros and special forms). Take for instance, arithmetic operators. In most languages, the compiler is able to natively recognize operators such as [
+ - / *] and assign special meanings depending on the context where they are used and for that reason must, among other things, differentiate between unary, binary and ternary operators. In Lisp however, these are all function calls!The general form of a function call is like so:
(function-name [arg1 arg2 ... argN])As is perhaps obvious, a function call is expressed simply as a list where the first element is considered to be the function name and everything else its arguments. As always, the arguments can be Lisp s-expressions themselves. If you wanted to add 2 numbers for instance, here's what you'd do:
(+ 1 2)Here,
+is the name of the function being invoked and1and2are its arguments. The function+can accept a variable number of arguments (like the Cprintffunction), which means that in order to add 4 numbers for instance, you can simply do this:(+ 1 2 3 4)You can build compound lists by nesting s-expressions like so:
(+ 1 2 (+ 3 4))Lisp will always evaluate the function arguments first from left to right (evaluating nested s-expressions if any) and only then invoke the function with the result of evaluating the argument forms. In the example above therefore, it will evaluate
1and2first - which evaluate to themselves, i.e.1and2- followed by(+ 3 4)- which evaluates to7. The resulting 3 numbers (1,2and7) are then passed to+which evaluates the composite expression to the value10.
There's a lot more that one can say about functions. I'll cover some of it in a subsequent post and also talk a bit about macros (which while a rather unique feature of Lisp is also at the same time quite powerful) and special forms.